Elastic Channels
Channels are one of the basic concurrency primitives provided by Go(lang) for goroutine communication and synchronization. Two types of channels are supported by the language: Unbuffered channels for synchronous operations (a write on an unbuffered channel blocks until a read is issued on the same channel, and vice-versa) and buffered channels that can be used to exchange data asynchronously (they work like concurrency-safe queues or mailboxes).
Go’s buffered channels have fixed buffers the size of which is specified at channel-creation time. While this is adequate for most uses, there are cases where channels with growable (virtually unlimited) buffers would be convenient. Fortunately, we can simulate such elastic channels by using pairs of “normal” channels connected by goroutines that do the buffer management. Something like this:
cout cin
+---------+ +---------+
| | |<----+ +-----| | |
+---------+ | | +---------+
. | V .
. +----+-----------------+----+ .
. | | | | .
. | +---[][][][][]<---+ | .
. | internal dynamic buffer | .
. +---------------------------+ .
. goroutine .
. .
. <------------------< .
............< R | S <...............
< eceive | end <
<------------------<
elastic channel
Sends to cin are received by the goroutine and either forwarded
directly to cout (if cout is ready to receive) or temporarily
stored in some form of internal dynamic buffer managed by the
goroutine. Similarly, receives from cout cause the goroutine to
dequeue data from its internal buffers and send them to cout. What
the user sees as a single elastic channel is actually the send-end of
the cin channel and the receive-end of cout.
A type like this could be used to represent an elastic channel of element-type T:
type ElasticT struct {
R <-chan T
S chan<- T
}
Since Go has no generic types, the element-type for the channel must
be parametrized manually (or using some custom code-generation
method). Alternatively, we could define an elastic channel of type
interface{} which can work for all value types (if we don’t care
about boxing and unboxing overheads):
type Elastic struct {
R <-chan interface{}
S chan<- interface{}
}
Anyway, we won’t concern ourselves with such type-parametric issues in this discussion. The user could use such channels (interface{} or type-specific) like this:
c := NewElasticT()
// Producers sends data on channel
go Producer(c.S)
// Consumer receives data from channel
go Consumer(c.R)
When a new elastic channel is created, the two channels (cin and
cout) are made, and the respective goroutine is started. The
goroutine is given the receive-end of cin and the send-end of
cout, while to the user the opposite ends are returned: the send-end
of cin (as c.S) and the receive end of cout (as c.R). It could
look like this:
const (
sendBuffer = 128
receiveBuffer = 128
)
func NewElasticT() ElasticT {
cin := make(chan T, sendBuffer)
cout := make(chan T, receiveBuffer)
e := ElasticT{S: cin, R: cout}
go elasticRun(cout, cin)
return e
}
To improve performance we have added a small fixed buffer to each of
cin and cout (sized for sendBuffer, and receiveBuffer items,
respectively). This is by no means necessary; our approach also works
with unbuffered channels. What remains is the goroutine that “sits
between” cin and cout and does the buffering. The general idea
looks like this (in pseudo-code):
out = nil
for {
select {
case vi := <- cin:
if out == nil
vo = vi
out = cout
else
q_push(vin)
case out <- vo:
if q_empty
out = nil
else
vo = q_pop()
}
}
We have two select clauses: an input clause receiving from channel
cin and enqueuing data, and an output clause, dequeuing data and
sending them to cout. Whenever the queue gets empty (and initially,
since the queue is initially empty) we disable the output
clause. Whenever the queue gets non-empty (i.e. when we push something
to it) we enable the output clause. This selective enabling /
disabling of the output select-clause is achieved by using the local
channel-typed variable out which is set to nil, when we want to
disable the clause, or to the output channel value, when we want to
enable it. Remember that clauses with operations (sends or receives)
on the nil channel are never selected. This idiom is quite common
and very handy since it allows us to implicitly introduce states to
our processing loop. Without it, the states would have to be explicit,
which results in more verbose and repetitive code (especially if,
unlike our example, there are several select-clauses common in
multiple states). Without this “nil trick” our (pseudo)-code would
look like this:
state = output_disabled
for {
switch state {
case output_disabled:
vi := <- cin:
vo = vi
state = output_enabled
case output_enabled:
select {
case vi := <- cin:
q_push(vin)
case cout <- vo:
if q_empty
state = output_disabled
else
vo = q_pop()
}
}
}
Having seen how the goroutine will operate in principle, let’s see the real implementation. First we have to decide on a queuing method: We need some form of dynamic FIFO queue which grows and shrinks as we add or remove elements to or from it. A doubly linked list, for example, would look ideal, or a ring-buffer. But for the moment, let’s forgo this decision, and assume that, whatever its implementation is, our queue will provide the following methods:
// Returns a new queue
func newQT() *QT
// Check if queue empty
func (q *QT) Empty() bool
// Enqueue element
func (q *QT) PushBack(el T)
// Dequeue element.
// ok==false: cannot dequeue, queue empty.
func (q *QT) PopFront() (el T, ok bool)
With this interface decided, we can now look at the real goroutine implementation, which goes like this:
func elasticRun(cout chan<- T, cin <-chan T) {
var in <-chan T
var out chan<- T
var vi, vo T
var ok bool
q := newQT()
in, out = cin, nil
for {
select {
case vi, ok = <-in:
if !ok {
if out == nil {
close(cout)
return
}
in = nil
break
}
if out == nil {
vo = vi
out = cout
} else {
q.PushBack(vi)
}
case out <- vo:
vo, ok = q.PopFront()
if !ok {
if in == nil {
close(cout)
return
}
out = nil
}
}
}
}
The only diversion from our pseudo-code model is the addition of some logic to properly handle the goroutine’s termination condition (i.e. what happens when our input channel is closed).
About the queue: While a linked list looks ideal (O1 insertions and deletions, ability to grow and shrink arbitrarily, etc.), in reality it will rarely outperform an array / slice based implementation even if the later shifts (copies) the elements back and forth for insertions and deletions. In almost all cases the list implementation will under-perform dramatically due to its inherently bad locality of memory accesses. You don’t have to take my word for it; you can listen to Bjarne instead. In order to implement queue operations with a slice the most straightforward approach is like this:
q = []T{}
For pushes (we add new elements to the back of the array):
q = append(q, el)
For pops (we remove elements from the front):
var zero T
el = q[0]
copy(q, q[1:])
q[len(q)-1] = zero
q = q[:len(q)-1]
return el
But is this the best we chan do? It isn’t. We can instead treat the slice as a circular buffer which allows us to do pushes and pops without having to copy elements back and forth. A circular buffer is a pre-allocated slice with two pointers (indexes) s and e indicating where the beginning and where the end of our queue are (respectively). After, say, four pushes our circular queue (of size eight) will look like this:
0 1 2 3 4 5 6 7
+--+--+--+--+--+--+--+--+
| | | | | | | | |
+--+--+--+--+--+--+--+--+
^ ^
| |
s e
In order to push an element we simply add the element where e points and increment e, modulo the size of the slice. In order to pop an element we simply increment s, again modulo the size of the slice. When our slice is full, we allocate a larger one (e.g. double in size) and copy the elements over. One issue, when implementing circular queues, is being able to decide if our queue is full or empty. That is, is a queue like this:
0 1 2 3 4 5 6 7
+--+--+--+--+--+--+--+--+
| | | | | | | | |
+--+--+--+--+--+--+--+--+
^
|
s
e
completely full, or empty? Several approaches exists: Using separate flags, reserving a slice-slot as sentinel, and so on. One of the most elegant (and the one we will apply) is to use free running indexes. This approach has the limitation of only working for slices whose size is a power of 2 (not for arbitrarily sized slices), but since we plan to double the size of our slice when it fills-up, anyway, we ‘re fine with this. Giving up the ability to use arbitrarily sized slices, buys us a very fast implementation that is completely devoid of special cases.
First, since the size of our slice is guaranteed to be a power of 2, we can do modulo arithmetic with masks. That is, x % size effectively becomes x & (size-1). Lest call this size-1 our current mask, or m. Second, the idea behind the free-running indexes implementation is to allow the s and e “indexes” be free running unsigned integers that roll-over when they reach their maximum value (2^32-1 if we use uint32’s) and roll-under when they reach zero. Queue operations and predicates then become trivial.
Is empty?
return s == e
Is full?
return e-s == sz
Push back:
q[e&m] = el
e++
Pop front:
el = q[s]
q[s&m] = zero
s++
return el
The only “costly” operation is to increase (double) the size of the slice, when it fills up, which forces us to copy all elements over to a new array. This can be implemented along these lines.
nSz = sz << 1 // twice as big
q1 := make([]T, 0, nSz)
si, ei := s&m, e&m
if si < ei {
q1 = append(q1, q[si:ei]...)
} else {
q1 = append(q1, q[si:]...)
q1 = append(q1, q[:ei]...)
}
q = q1[:nSz]
s, e = 0, e-s
sz = nSz
m = nSz - 1
Exactly the same can be used when we want to shrink-back our slice.
Back to our channels: Now that we have all the parts in place we can measure the performance of our implementation. We compare with “normal” non-elastic channels, unbuffered, and buffered. Our trivial benchmarking code looks like this:
func consume(n int, c <-chan T, end chan<- int) {
var i int
for i = 0; i < n; i++ {
q := <-c
if q != T(i) {
break
}
}
end <- i
}
func produce(n int, c chan<- T, end chan<- int) {
var i int
for i = 0; i < n; i++ {
c <- T(i)
}
close(c)
end <- i
}
func benchFixed(b *testing.B, buffer int) {
c := make(chan T, buffer)
end := make(chan int)
b.ResetTimer()
go produce(b.N, c, end)
go consume(b.N, c, end)
<-end
<-end
b.StopTimer()
}
func benchCon(b *testing.B, mode ShrinkMode) {
elc := NewElasticT1(mode)
end := make(chan int)
b.ResetTimer()
go produce(b.N, elc.S, end)
go consume(b.N, elc.R, end)
<-end
<-end
b.StopTimer()
}
func benchSeq(b *testing.B, mode ShrinkMode) {
elc := NewElasticT1(mode)
end := make(chan int)
b.ResetTimer()
go produce(b.N, elc.S, end)
<-end
go consume(b.N, elc.R, end)
<-end
b.StopTimer()
}
For the elastic channels test benchSeq runs the producer and the
consumer in sequence; the producer fills the elastic buffer and stops,
then the consumer is started to drain it. Test benchCon runs the
producer and the consumer concurrently (real-world cases will be
somewhere in between). The the results on my computer:
BenchmarkFixedNoBuf 5000000 425 ns/op
BenchmarkFixed1024 10000000 215 ns/op
BenchmarkSeq 1000000 1599 ns/op
BenchmarkCon 1000000 1974 ns/op
That is, our elastic channels seem to be approximately 4x slower than
an unbuffered channel and about 7x - 9x slower than a buffered one. We
can’t do much to improve things (after all we allocate memory, we copy
things over when we do, so, unavoidably, we will run slower than the
fixed-buffer channels) but perhaps we can still do a bit more… Using
the excellent
Go CPU Profiler (pprof)
we get a graph like this (focused on the elasticRun function and its
callees, and trimmed a bit around the edges to better fit our
picture):

It’s clear that our program spends about half of its time in
selectgo (obviously the runtime’s select-statement
implementation). If we instead focus on the queue operations (pop,
push, resize, etc.) we see that they take a relatively modest portion
of our program’s execution time:
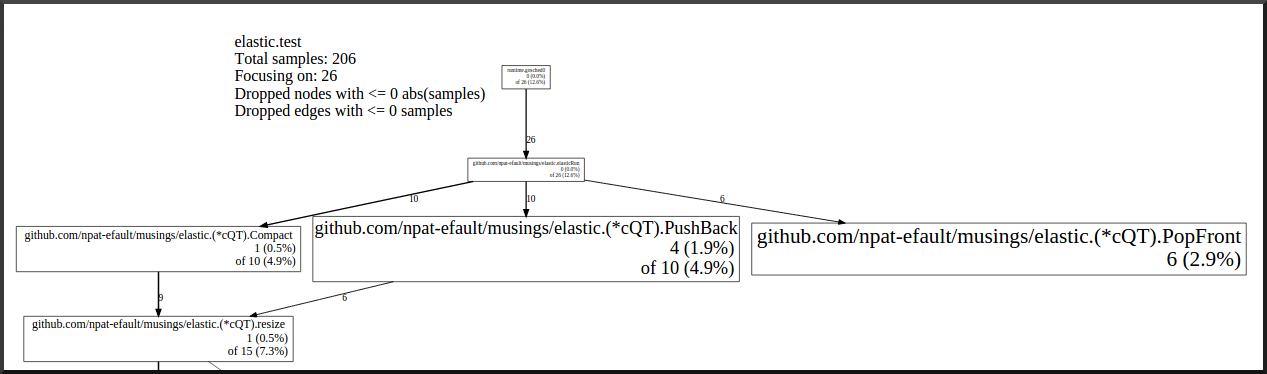
(Or you can see the complete CPU profiler graph of our benchmark run)
{kind=link}
We know that, in general, “select” is a costly operation compared to
plain channel sends or receives, and our goroutine does a lot of them
(so it will certainly be slower than a benchmark that does no selects
whatsoever). Can we do something to reduce the number of selects in
our goroutine? Turns out, we can. We can modify our code so that,
once we receive something from the input channel and enqueue it, we
can, instead of going back to the select statement, receive again from
the input channel, and again, and again, until we block. The same for
the output direction: Once we write something to outc we can
immediately try to write once more, and once more, until we block. The
elasticRun function now becomes:
const maxReceive = 1024
func elasticRun1(mode ShrinkMode, cout chan<- T, cin <-chan T) {
var in <-chan T
var out chan<- T
var vi, vo T
var ok bool
q := newQT()
in, out = cin, nil
for {
select {
case vi, ok = <-in:
inLoop:
for i := 0; i < maxReceive; i++ {
if !ok {
if out == nil {
close(cout)
return
}
in = nil
break
}
if out == nil {
vo = vi
out = cout
} else {
q.PushBack(vi)
}
select {
case vi, ok = <-in:
default:
break inLoop
}
}
case out <- vo:
outLoop:
for {
vo, ok = q.PopFront()
if !ok {
if in == nil {
close(cout)
return
}
out = nil
}
select {
case out <- vo:
default:
break outLoop
}
}
}
}
}
The maxReceive test is put to make sure that in, the very unlikely,
case a fast writer constantly writes to our cin channel, we will
still, eventually, get the chance to send some output. With this
optimization in place the benchmark results improve considerably:
BenchmarkFixedNoBuf 5000000 403 ns/op
BenchmarkFixed1024 10000000 212 ns/op
BenchmarkSeq 5000000 562 ns/op
BenchmarkCon 5000000 637 ns/op
Now our elastic channels are just 1.5x slower than unbuffered “normal” channels and only 2.5x to 3x slower than buffered ones. Compared to the “unoptimized” implementation tested above they are roughly 3x faster.
What is interesting is that if we increase the number of threads used by the runtime to 4 (GOMAXPROCS=4, remember we have 1 consumer, 1 producer, and the elastic goroutine in-between) things get much better still (on my notebook computer which has 2 CPU cores)
BenchmarkFixedNoBuf-4 5000000 553 ns/op
BenchmarkFixed1024-4 5000000 406 ns/op
BenchmarkSeq-4 5000000 407 ns/op
BenchmarkCon-4 5000000 396 ns/op
There is still room for optimizations and tweaking: We could, for example, start with an allocated queue of a certain size (to avoid initial allocations and copies), we could shrink the queue more lazily, or even not at all, and so on. Depending on the elastic channel usage pattern these may have considerable effect, or not.
You can find the complete code for the elastic channels, the tests, and the benchmarks here: